初めに
この章のテーマは、「より使いやすいデータベースにするにはどうしたらよいか」となります。そのためには、デフォルトのままではどのようになるのか、それではどのような問題があるのか、どのようになると使いよいのか、そして具体的にはどのような方法で実現するのかを検討していくことになります。
この章のテーマは、「より使いやすいデータベースにするにはどうしたらよいか」となります。そのためには、デフォルトのままではどのようになるのか、それではどのような問題があるのか、どのようになると使いよいのか、そして具体的にはどのような方法で実現するのかを検討していくことになります。
Java EE には、データベースを操作するための仕様である JPA が規定されています。もともと Java にはデータベース操作の仕様として JDBC という規約がありました。ただしこの規約は低レベルの操作の規約です。データベースやテーブルといったものを強く意識して、 SQL を構築してデータベースを操作していくものになります。これまでのデータベース操作に慣れた人には了解は易しいものです。
一方 JPA はより高度にデータベースをモデル化したものになっており、利用しているデータベースやテーブルといったものを意識させません。Java のクラスを操作することが、間接的にデータベースの操作に翻訳されることになります。より直接的には、プログラムで SQL 文を構築するといった必要性が少なくなります。今回のサンプルでは SQL 文を構築することは全く行いませんでした。今までのデータベース操作とは考え方を大きく変えることを求められます。
技術的には、発行される SQL が正面に現れませんので、問題が起こった場合の原因調査や十分な速度が得られない場合のチューニングなどに、今までになかった手段を要求されるようになります。
さて、標準の JPA を使用した場合、データベース関連の操作は EntityManager クラスとエンティティクラスとで行います。分かりやすいのはエンティティクラスです。このクラスはデータベースのテーブルないしビューに対応したクラスです。
テーブルの1レコードやビューの1レコードはエンティティクラスの1インスタンスになります。1レコードを構成する多くのフィールドをインスタンス変数に持ち、それぞれのインスタンス変数を操作するための getter/setter メソッドをもつ比較的単純な構造のクラスになります。こうしたクラスは、すでにテーブルやビューが存在していれば、 NetBeans から直接ソースを作ることができます。そうして自動作成したソースに適宜修正を加えることになります。修正作業が不要となることもあるでしょう。
一方 EntityManager クラスは JPA 標準のクラスです。EntityManager クラスから検索すると該当するエンティティクラスのインスタンスが返されますし、必要なエンティティクラスのインスタンスを EntityManager に渡すことで、データの追加・変更・削除が自動的に行われます。ここまでは便利そうなのですが、 EntityManager クラスのインスタンスの管理が Web サーバにより自動化されているのです。つまり、いつ EntityManager のインスタンスが作成され、いつ廃棄されるのかがプログラマーから隠されているのです。
なにも問題が発生しないとしたら、面倒なことはしたくないので便利な仕様と思います。しかし実際にはそうはいきません。データベースを操作した時のエラー処理は重要な管理要件となります。エラーが発生した場合にどのような処理をすべきなのかは、アプリケーション毎にハンドリングすることが必須です。単純にエラーメッセージをブラウザに表示するだけでよいのか、サーバ上のエラーログに残す必要があるのか、エラーからの修復動作はどうあるべきか、等々難しい問題ばかりです。このエラー処理は Web サーバの標準動作にまかすわけにいかないのです。
EntityManager クラスと同等の機能をプログラマの管理下で利用するには、EntityManagerFactory クラスと UserTransaction クラスの標準クラスを使用します。前者は名前から分かるように、必要なタイミングで EntityManager のインスタンスを生成するためのファクトリメソッドを持つクラスです。後者は、プログラムの管理下でトランザクションを実施するためのクラスになります。エンティティクラスは今までと同じに利用します。次の章では、どのような構成にすればより使いやすくなるかを検討します。
結論を書けば、ブラウザ用の画面を構築するための仕様である JSF 用と、データベースを操作するための仕様である JPA 用の、より高機能にラップしたクラスからなるライブラリを作ることになります。 ここ にある JavaLibrary_for_JSF_JPA.jar がそれになります。
全体のモデル図を以下に示します。
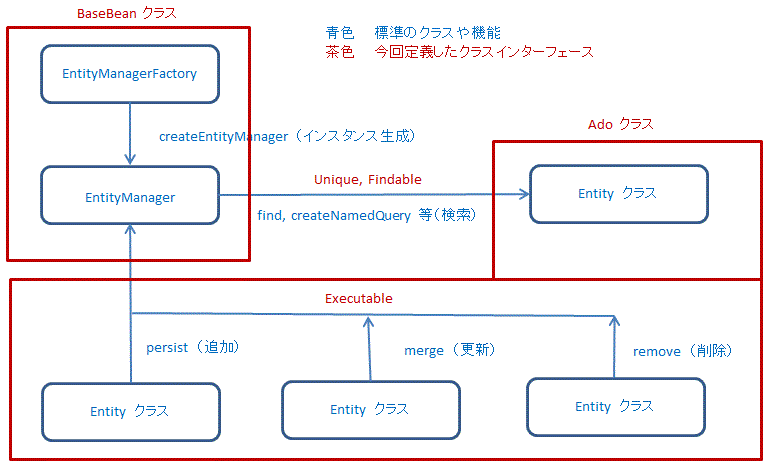
最初の問題は必須クラスである EntityManagerFactory と UserTransaction クラスのインスタンスをどのクラスに持たせるか?これは簡単に答えがでました。ブラウザに返す画面構成は JSF に従った xhtml ファイルに記述します。その画面構成に必要なデータそのものは、Java のクラスである管理Bean が持つことになります。そこですべての管理Bean の親クラスとなるクラスを定義して、そのクラスの所有とします。個々の画面毎の管理Bean クラスはその親クラスから派生して作成することになります。
次の問題は、データベースに関係する機能をどのように設計するか?これはやや難しい問題と思います。これは、以下の2種類のクラス/インターフェースを組み合わせることで解決することにしました。
まずはインターフェース。データベースの操作を抽象化した3つのインターフェースを定義します。
| インターフェース名 | 説明 |
|---|---|
| Unique | プライマリーキーを指定して検索し、1エンティティクラスのインスタンスを返すためのインターフェース |
| Findable | 条件を指定して検索し、複数のエンティティクラスのインスタンスを返すためのインターフェース |
| Executable | 追加・変更・削除の処理を1トランザクションとして実行するためのインターフェース |
Unique インターフェースと Findable インターフェースはデータ検索用のインターフェースで、Executable インターフェースは更新系の処理を行うためのインターフェースとなります。
次はクラス。原則として、各テーブルごとにクラスを定義して、上記の3つのインターフェースの実体を定義するものになります。ここら辺は、以下の章の実装を見ていただいた方が分かりやすいでしょう。
すべての管理Bean の親となるクラスを定義します。名前は BaseBean としました。まずはソース(部分)をご覧ください。実際に試す場合には、JDK のライブラリと Java EE 7 のライブラリを参照する操作をしてください。その上で、必要なクラスを import してください。NetBeans を使用していれば、import の作業はほぼ自動的に対応してくれます。ソースには、このクラス自体が含まれる package や、使用している import は省いてあります。package はご希望に合わせてどうぞ。
abstract public class BaseBean {
@PersistenceUnit
protected EntityManagerFactory emf;
@Resource
protected UserTransaction utx;
/**
* Creates a new instance of BaseBean
*/
public BaseBean() { }
}
「{」「}」の書式は私の好みです。クラス定義の「abstract」は必ず派生クラスを定義する必要を明示したものです。「@PersistenceUnit」「@Resource」は CDI の機能になります。データベースに関連する部分はプログラマの管理下に置きたいけれども、 Web サーバで自動化できる部分はその恩恵を得たいためです。2つのクラスのインスタンスは BaseBean のインスタンス変数としています。どちらのインスタンス生成も Web サーバに任せています。アクセス修飾子はどちらも「protected」としています。これも私の設計上の好みです。派生クラスから直接操作する必要が高いインスタンス変数であると判断した場合に protected とし、公開メソッドをわざわざ用意しないというのが好きです。protected ですので、派生クラスからは変数名で直接操作できます。それくらいは、子供のクラスを信用してあげようということ。なにもしないコンストラクタを用意してあります。
1件のデータを検索するメソッドのソース(部分)は以下になります。
public Object select(Unique obj)
{
Object item = null;
EntityManager em = null;
try
{
em = emf.createEntityManager();
item = obj.select(em);
}
catch (Exception ex)
{
errorOccurred(ex);
}
finally
{
if (em != null)
em.close();
}
return item;
}
プライマリキーによる検索処理の実装はデータベースのテーブルに対応したクラスで行います。そのクラスは、次の章のテーマになります。 BaseBean クラスは実際の検索処理の内容は知りません。しかしテーブルクラスが作成したオブジェクトを使って、1件の検索処理を起動し、エラーが発生した場合の対処方法を一元化しています。
Unique インターフェースを実装したオブジェクトを引数にもらい、検索結果のオブジェクトを返します。実際にはエンティティクラスのインスタンスを返すことになります。処理の詳細説明は、 EntityManagerFactory から EntityManager のインスタンスを作ります。その後、引数のオブジェクトに対して select メソッドを呼び出します。問題はエラーが発生した時の処理になります。errorOccurred メソッドを呼び出しています。必要に応じて派生クラスでこのメソッドをオーバーライドして再定義することを想定しています。
複数のデータを検索するメソッドのソース(部分)は以下になります。
public List select(Findable obj)
{
List list = new ArrayList();
EntityManager em = null;
try
{
em = emf.createEntityManager();
list = obj.select(em);
}
catch (Exception ex)
{
errorOccurred(ex);
}
finally
{
if (em != null)
em.close();
}
return list;
}
構造は1件の場合と同じです。違いは、複数の検索結果を返す必要がありますから、戻り値にリストを使用することくらいです。
次はトランザクションの処理用のソース(部分)です。
@SuppressWarnings("UseSpecificCatch")
public boolean transact(List<Executable> objs)
{
boolean flag = true;
EntityManager em = null;
try
{
utx.begin();
em = emf.createEntityManager();
for (int i = 0, size = objs.size(); i < size; ++i)
objs.get(i).execute(em);
utx.commit();
}
catch(Exception ex)
{
flag = false;
try
{
utx.rollback();
} catch (Exception e) { }
errorOccurred(ex);
}
finally
{
if (em != null)
em.close();
}
return flag;
}
引数として Executable インターフェースを実装したオブジェクトのリストをもらいます。このリストの全要素が1トランザクションとして処理されます。
処理内容を見ていきましょう。トランザクションを開始します。その後、EntityManagerFactory から EntityManager を作ります。引数のリスト分だけ処理を繰り返します。エラー無く終了した場合に、コミットを呼び出します。エラーが発生した場合にロールバックを実行し、エラー処理の errorOccurred メソッドを呼び出します。
最後にエラー処理に関連したメソッドを見てみます。
public void errorOccurred(Exception ex)
{
errorOccurred(ex.getMessage());
}
public void errorOccurred(String msg)
{
errorOccurred(null, msg);
}
public void errorOccurred(String key, String msg)
{
FacesContext.getCurrentInstance().addMessage(key, new FacesMessage(FacesMessage.SEVERITY_ERROR, msg, null));
}
public void infoOccurred(String msg)
{
infoOccurred(null, msg);
}
public void infoOccurred(String key, String msg)
{
FacesContext.getCurrentInstance().addMessage(key, new FacesMessage(FacesMessage.SEVERITY_INFO, msg, null));
}
public void warnOccurred(String msg)
{
warnOccurred(null, msg);
}
public void warnOccurred(String key, String msg)
{
FacesContext.getCurrentInstance().addMessage(key, new FacesMessage(FacesMessage.SEVERITY_WARN, msg, null));
}
7つのメソッドがありますが、易しい内容です。エラー表示用・警告表示用・情報表示用の違いがあるだけです。その違いはメソッド名で明らかでしょう。
1つだけ JSF のメッセージ処理を知らないと分からないものがあります。JSF にはメッセージの特別処理の機能があります。具体的に言えば、メッセージ表示用の2種類のタグが用意されています。メッセージを表示するさい、特定の対象を指定して表示場所を決めるもの(実際には HTML の id 属性を指定することで可能になる)と、全ての表示内容をまとめて HTML の1タグに表示するものとがあります。
2引数の errorOccurred メソッドを例にしましょう。FacesContext.getCurrentInstance() により、現在処理中の JSF オブジェクトを参照できます。そのオブジェクトに対して、addMessage メソッドで表示内容を追加できます。addMessage メソッドの第一引数は表示する HTML のタグの id 属性の値を指定します。 null を指定した場合は、全ての内容を1ケ所で表示する専用のタグを指定したことになります。第2引数はそのメッセージの属性を指定します。エラーなのか、警告なのか、ただの情報なのかで書式が変わります。
データベースに関連したクラスはやや複雑です。初めて見る Java プログラムの記述となるかもしれません。
まずはインターフェースのソース(部分)です。ここでは1つにまとめてありますが、Java では1インターフェース1ファイルになります。
public interface Unique {
public Object select(EntityManager em) throws Exception;
}
public interface Findable {
public List select(EntityManager em) throws Exception;
}
public interface Executable {
void execute(EntityManager tm) throws Exception;
}
それぞれ引数に EntityManager をとります。その EntityManager の機能を利用して、それぞれ1件の検索、複数の検索、データベースの更新を行うためのインターフェースです。何らかのエラーが発生した場合には、例外を投げる仕様です。
ライブラリとしてまとめてあるのは、上記の1クラス(BaseBean)と3インターフェース(Unique Findable Executable)だけです。NetBeans を使用して jar ファイルを作成します。個々の Web アプリケーションでは、作成したこの独自ライブラリを参照して利用することになります。
次に上記インターフェースを実装しているクラスを見てみましょう。これらのクラスは原則として、データベースのテーブルの数だけ用意する想定です。またビューに対応するクラスを用意することも考えられます。その場合、ビューにはプライマリキーフィールドは想定しずらいですし、追加・変更・削除も必要ないでしょうから、 Findable インターフェースだけを実装することになるでしょう。クラスとしてMajor クラスを取り上げます(部分)。
public class MajorDao {
@SuppressWarnings("Convert2Lambda")
public Unique uniqueKey(final String key)
{
return new Unique() {
@Override
public Major select(EntityManager em) throws Exception
{
return em.find(Major.class, key);
}
};
}
}
ここでは Unique インターフェースの実装だけを取り上げます。クラスの名前は MajorDao としました。「@SuppressWarnings("Convert2Lambda")」は、NetBeans の警告を表示させないための記述です。気にしなくても大丈夫。
uniqueKey メソッドがあります。このメソッドは引数を1つもち、戻り値として Unique インターフェースを実装したオブジェクトを返します。このメソッドの役割は、 Major テーブルのプライマリキーを指定して、1件の検索を実行できるオブジェクトを作成することです。大事なことは、検索結果を返すのでは ない ということです。どのようにしたら検索できるかという、その方法を知っているオブジェクトを返すことになります。実際に検索を行うのは、このメソッドが返したオブジェクトを引数として BaseBean クラスの select(Unique obj) を呼び出したときになります。
どのようにしてこの機能を実現するか?その答えは、無名内部クラスを使用することとなります。処理内容を見ましょう。処理の大枠は「return new Unique();」となっています。Unique はインターフェースであり、クラスではありません。それにも拘わらす、 new でインスタンスを作成して、そのオブジェクトを返しています。実はインターフェースに対して new とすると、コンパイラがそのインターフェースを定義したクラスを自動的に作成してくれるのです。もちろんそのクラスにはクラス名がありません。そのため”無名”クラスとなります。さらにこの無名クラスは、 MajorDao クラスの内部で定義されています。つまりは”内部”クラスです。この2つの性格を持つところから無名内部クラスとなります。
この無名内部クラスは Unique インターフェースを実装している必要があります。具体的には、「public Object select(EntityManager em) throws Exception;」を定義する必要があります。その実装を見てみましょう。まず戻り値は Object ではなく Major クラスのインスタンスとなります。この Major クラスはエンティティクラスであり、 NetBeans を使用してデータベースの Major テーブルから自動作成しました。検索処理自体は、 EntityManager のメソッド find を呼び出しているだけです。find メソッドは EntityManager が標準で提供しているメソッドです。
ここでもう一つ驚くのは、検索条件である引数 key の扱いかもしれません。この引数は uniqueKey メソッドの引数です。そして uniqueKey メソッドは検索結果を返すのではなく、検索のやり方を知っているオブジェクトを返すのが役割です。実際に検索が行われるのはいつになるかは分かりません。しかしこうやって返されたオブジェクトは、自分が生成された時の検索条件を記憶しており、処理が本当に発火した時点で正しく検索することが可能になります。ただし、オブジェクトが生成された後で引数 key が変更されないことを意味する「final」をつけなければいけません。
テーブル Major のプライマリキーは文字列型の1フィールドだけですので、 uniqueKey メソッドの引数はこの定義で問題がありません。より複雑なプライマリーキーを持つテーブルの場合は、そのように引数を変更する必要があります。
Findable の実装コード(部分)だけのせます。 EntityManager のメソッド createNamedQuery を呼び出し、その返されるオブジェクトから getResultList を呼び出しています。なほ、Major.findAll という名前を持つ検索方法は、 NetBeans から Major エンティティクラスを自動作成すると作成されます。 Major エンティティクラスのソースを確認してください。
@SuppressWarnings("Convert2Lambda")
public Findable findAll()
{
return new Findable() {
@Override
public List select(EntityManager em) throws Exception
{
return em.createNamedQuery("Major.findAll").getResultList();
}
};
}
Executable の実装コード(部分)だけのせます。説明は省略します。実装は追加・変更・削除の3メソッドが必要になります。
public Executable insert(final Major aMajor)
{
return new Executable() {
@Override
public void execute(EntityManager em) throws Exception
{
aMajor.setCDate(new Date());
em.persist(aMajor);
}
};
}
public Executable update(final Major aMajor)
{
return new Executable() {
@Override
public void execute(EntityManager em) throws Exception
{
aMajor.setMDate(new Date());
em.merge(aMajor);
}
};
}
public Executable delete(final String key)
{
return new Executable() {
@Override
public void execute(EntityManager em) throws Exception
{
Major obj = em.find(Major.class, key);
em.remove(obj);
}
};
}
テーブルを表現したクラスはすべてで3つ作りました。以下のものです。
| クラス名 | 説明 |
|---|---|
| MajorDao | 大分類テーブルを操作するためのクラス。Major エンティティの検索・追加・変更・削除のメソッドを定義 |
| MinorDao | 小分類テーブルを操作するためのクラス。Minor エンティティの検索・追加・変更・削除のメソッドを定義 |
| KnowledgeDao | 知識テーブルを操作するためのクラス。Knowledge エンティティの検索・追加・変更・削除のメソッドを定義 |
MinorDao クラスは上記内容を参考にして作成してください。さほど難しくありません。
しかし KnowledgeDao クラスにはやや変わったメソッドを実装してあります。それはこのクラスを利用する画面では、ページングが必要になるためです。利用する画面をどのように設計するかで、データベースのクラスに用意しなければならないメソッドも変わってきます。ではそのソース(部分)です。
public Unique count(final String sql)
{
return new Unique() {
@Override
public Long select(EntityManager em) throws Exception
{
return em.createQuery(sql, Long.class).getSingleResult();
}
};
}
public Findable findPage(final int offset, final int limit, final String sql) {
return new Findable() {
@Override
public List select(EntityManager em) throws Exception
{
return em.createQuery(sql, Knowledge.class).setFirstResult(offset).setMaxResults(limit).getResultList();
}
};
}
count メソッドは検索に使用する SQL 文を引数として、その検索に該当する件数を得るためのメソッドです。当然 Unique インターフェースを実装することになります。ここで返されるオブジェクトを発火させた結果は、データの総数すなわち Long 型となります。findPage メソッドは、検索に使用する SQL 文と、ページングの開始ページ番号と1ページの件数を指定して、該当するデータを検索するためのものです。こちらは、Findable インターフェースを実装することになります。
上記メソッドのヘルパ的メソッドである、検索に使用する SQL を構築するための次のメソッド(部分)も用意してあります。
public String makeSql(KnowledgeCondition cond)
{
StringBuilder buf = new StringBuilder("select k from KnowledgeView k where 1 = 1 ");
buf.append(makeWhere(cond));
buf.append(" order by k.majorID, k.minorID, k.id ");
return buf.toString();
}
public String makeCountSql(KnowledgeCondition cond)
{
StringBuilder buf = new StringBuilder("select count(k) from Knowledge k where 1 = 1 ");
buf.append(makeWhere(cond));
return buf.toString();
}
private String makeWhere(KnowledgeCondition cond)
{
StringBuilder buf = new StringBuilder();
if (!cond.getMajorId().equals("-1")) {
buf.append(" and k.majorID = '");
buf.append(cond.getMajorId());
buf.append("'");
}
if (!cond.getMinorId().equals("-1")) {
buf.append(" and k.minorID = '");
buf.append(cond.getMinorId());
buf.append("'");
}
if (cond.getTitle().length() > 0) {
buf.append(" and k.title like '%");
buf.append(cond.getTitle());
buf.append("%'");
}
if (cond.getKeyword().length() > 0) {
buf.append(" and k.keyWord like '%");
buf.append(cond.getKeyword());
buf.append("%'");
}
return buf.toString();
}
makeSql メソッドは上記の findPage メソッドで使用する SQL 文を返します。 makeCountSql メソッドは上記の count メソッドで使用する SQL 文を返します。内部で SQL 文の where 節を構築するメソッドをさらに利用しています。この3つのメソッドの引数である、KnowledgeCondition は検索条件を表現したクラスです。インスタンス変数とその変数への getter/setter メソッドをもつ単純なクラスです。
具体的な検索条件は、 こちら を見てください。大分類、小分類、タイトル、キーワードの4つの条件を自由に組み合わせて検索します。その4つの条件に対応したクラスです。
これら以外のメソッドは MajorDao クラスと同様です。学習を兼ねて作成してみてください。
エンティティクラスはデータベースとやり取りをする、そのデータ自体を表現したクラスです。このクラスは直接ソースを記述するというよりも、まずデータベースを構築して、その構築したテーブルやビューから自動作成し、必要に応じて編集することをお勧めします。自動作成したソースを確認すれば、簡単にソースを記述できるようなものではないことは納得できると思います。
エンティティクラスを作成するにあたって、データベースの作成作業と、NetBeans の環境構築は済んでいるものとします。まだでしたらその作業を行ってください。
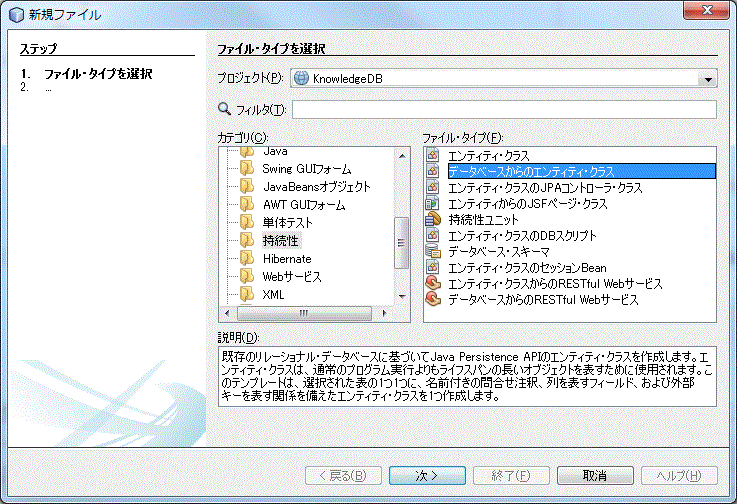
KnowledgeDB プロジェクトを選択した状態で、新規ファイルボタンをクリックします(または、メニューのファイル→新規ファイル)。すると新規ファイルダイアログが開きます。
「カテゴリ」で「持続性」を「ファイル・タイプ」で「データベースからのエンティティクラス」を選択し、「次へ」をクリックします。
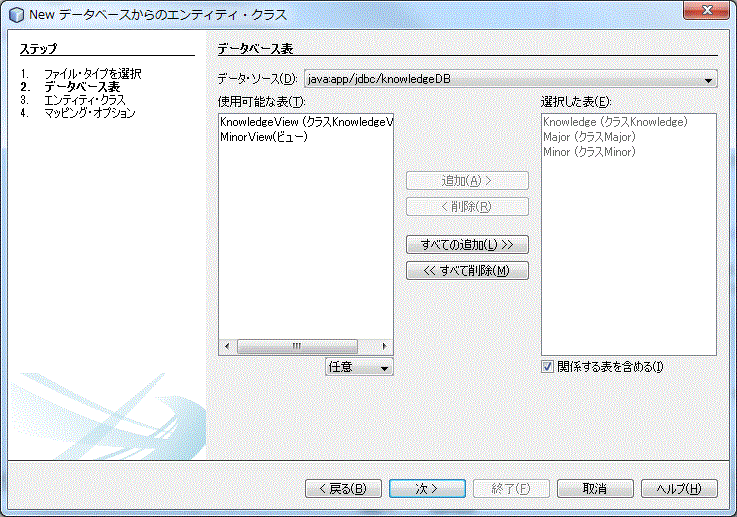
「データソース」から登録された登録済みのデータソースを選択します。不可解な点は、関連がありそうと思える名前が2つ表示されます。どうもひとつは NetBeans で登録した名前で、もう一つは GlassFish で登録した名前のように思われます。ここでは、前者を選択してください。
「使用可能な表」から今回は Major 、 Minor 、 Knowledge の3つを選択して、「選択した表」に移動させます。その後「次へ」をクリックします。
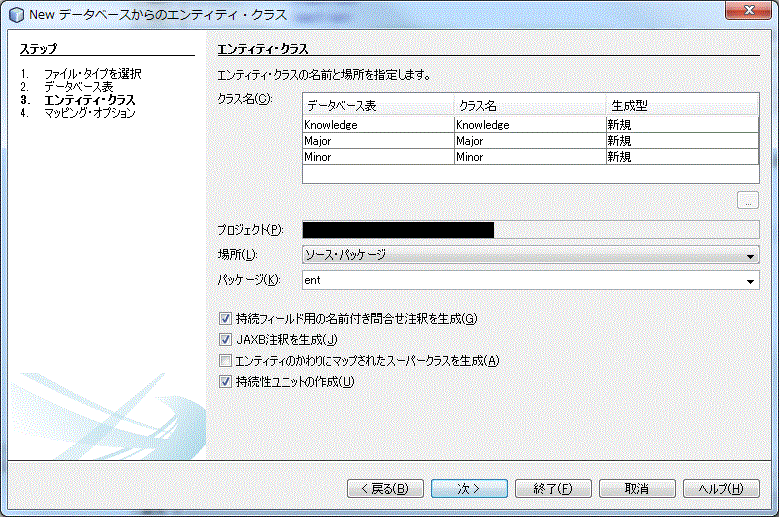
「パッケージ」を「ent」としました。この部分は任意に変更してください。(画面ショットの都合上プロジェクト名を隠してあります。同じプロジェクトには同名のエンティティクラスファイルが存在するため同じ操作手順ができません。別のプロジェクトを仮に借りて作業したためです。)
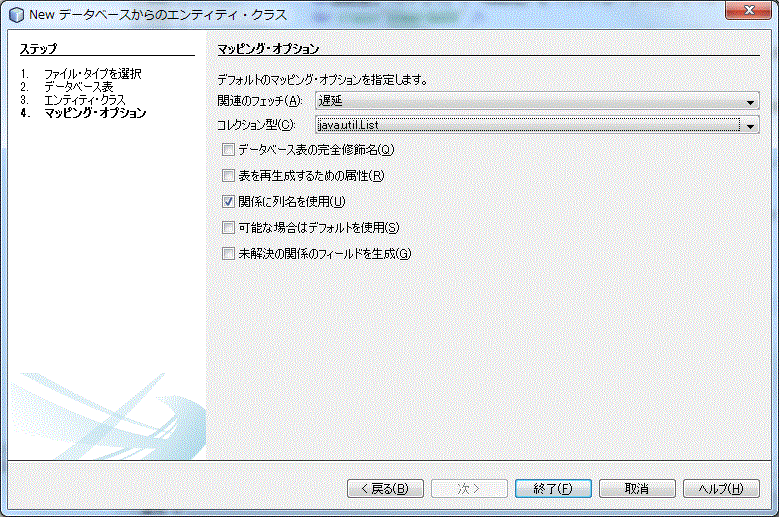
「関連のフェッチ」は必ず「遅延」を選択してください。「コレクション型」は「List」を選択しました。さて、説明になります。データベースにはリファレンスキー制約を利用するのが一般的です。2つのテーブル間で親子関係を定義するものになります。このサンプルでも Minor テーブルは Major テーブルのプライマリーキーフィールドを外部参照しています。関連のフェッチとは、この外部参照のデータをどのように扱うのかを指定します。デフォルトではある親テーブルを検索した場合、そのテーブルを外部参照している子テーブルの該当するデータも自動的に検索されます。そしてこの自動検索は、子から孫へと、外部参照のあるかぎり検索されます。当然検索結果はメモリに格納されますから、気が付かないうちに大量のメモリを消費することになりかねません。
このとき、「遅延」を選択しておくと動作が変わります。無条件に自動検索するのではなく、子データを格納した変数を参照した時に自動的に検索が実行されるようになります。最初の検索時に無条件に参照先が検索されるのではなく、本当に必要になるまで検索処理が”遅延”される動きになります。コレクション型は、このような1:N の対応となるその N 側のデータをどのようなデータ型で管理するかを指定するものです。私は List で管理することを選びました。
エンティティクラスを作成するためのテーブルを3つ選択しました。しかし自動的に作成されたクラスは4つあるはずです。それは、 Minor テーブルには複合プライマリキーを使用しているためです。複合プライマリーキーを使用していると、そのキーを表現したクラスが自動的に作成されます。MinorPK がそのクラスになります。
次はその複合プライマリーキーの問題を扱います。
データベースで複合プライマリーキーを使用していると、エンティティクラスは自動的に1つ増えてしまいます。またプログラムから操作する場合にも、エンティティクラスの中にもう1段エンティティクラスが存在して、見通しが悪くなるという問題があります。
しかし本当の問題は別にありました。Knowledge テーブルも MinorPK クラスを参照しています。これはこの知識がどの大分類と小分類に属しているかを示す重要な情報です。そして Knowledge テーブルの MinorPK の値は修正可能でなければなりません。データが増えてきたため、さらに大分類や小分類の種類を増やしたい。その場合に既存の知識の分類を訂正したいというのは当然の要望です。単純に、知識の分類を間違えて登録したので変更したいといった場合もあります。
ところが、Knowledge クラスの MinorPK を変更することができないのです。ソースを追う限りでは、 Knowledge クラスの MinorPK を変更する処理は、Minor テーブルのプライマリキーを変更することになるのです。プライマリーキーの変更を禁止するのは当然の仕様として納得できます。しかしいまやろうとしているのは Minor テーブルのプライマリキーではなく、それを外部参照している Knowledge の変更なのです。自動生成されたエンティティクラスではどのようにこの問題を回避したらよいのか分かりませんでした。
解決案として思いついた方法は2つです。データベースの構造自体を変更できる場合、複合プライマリーキーの使用をやめるというものです。業務上意味を持たないサロゲートキーを導入して、これをプライマリーキーにします。そしてそれまでのプライマリーキーにはユニーク制約を付けたり、高速化のためのインデックスを用意するという方法です。
残念ながら今回はこの方法はとれません。それはこのデータベースは、別のシステムで既に使用中であり、それらの関連するプログラムまで改修してまわることができないためです。そこで、いったん Knowledge テーブルの外部参照キー制約を削除します。その状態で NetBeans からエンティティクラスを自動作成します。次に外部参照を再度設定するという方法をとりました。この方法では、 Minor テーブルのプライマリーキーは複合のままなため、 MinorPK クラスは作られます。しかし Knowledge テーブルには参照が存在しませんので、ただの文字列とみなされます。
中途半端な対応ですが、このサンプルではこの方針で正しく動作させることができました。
自動作成されたエンティティクラスをそのまま無修正で使用できればよいのですが、そうはいかない場合もあります。それでは作成されたエンティティクラスを見てみましょう。Major クラスです(部分)。
@Entity
@Table(name = "Major")
@XmlRootElement
@NamedQueries({
@NamedQuery(name = "Major.findAll", query = "SELECT m FROM Major m"),
@NamedQuery(name = "Major.findById", query = "SELECT m FROM Major m WHERE m.id = :id"),
@NamedQuery(name = "Major.findByName", query = "SELECT m FROM Major m WHERE m.name = :name"),
@NamedQuery(name = "Major.findByComment", query = "SELECT m FROM Major m WHERE m.comment = :comment"),
@NamedQuery(name = "Major.findByCDate", query = "SELECT m FROM Major m WHERE m.cDate = :cDate"),
@NamedQuery(name = "Major.findByMDate", query = "SELECT m FROM Major m WHERE m.mDate = :mDate")})
public class Major implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@Basic(optional = false)
@NotNull
@Size(min = 1, max = 2)
@Column(name = "ID")
private String id;
@Basic(optional = false)
@NotNull
@Size(min = 1, max = 20)
@Column(name = "Name")
private String name;
@Size(max = 128)
@Column(name = "Comment")
private String comment;
@Basic(optional = false)
@NotNull
@Column(name = "CDate")
@Temporal(TemporalType.TIMESTAMP)
private Date cDate;
@Column(name = "MDate")
@Temporal(TemporalType.TIMESTAMP)
private Date mDate;
@Basic(optional = false)
@NotNull
@Lob
@Column(name = "Stamp")
private byte[] stamp;
@OneToOne(cascade = CascadeType.ALL, mappedBy = "major1", fetch = FetchType.LAZY)
private Major major;
@JoinColumn(name = "ID", referencedColumnName = "ID", insertable = false, updatable = false)
@OneToOne(optional = false, fetch = FetchType.LAZY)
private Major major1;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "major", fetch = FetchType.LAZY)
private List<Minor> minorList;
}
「@Entity」はこのクラスがエンティティクラスであることを示します。「@Table(name = "Major")」は対応するテーブルの名前が Major であることを示します。「@NamedQueries」は EntityManager が検索時に使用できる、名前を付けた検索条件になります。自動的に作成したものですから、すべてのフィールドで検索できるようになっています。必要がないと判断した項目は削除できますし、この内容をまねて新たな検索方法を追加することもできます。ちなみに、「findAll」は全件検索用、「findById」はプライマリーキーを使用した検索用です。それ以外の項目は削除しても大丈夫でしょう。
この後は、テーブルの各フィールドに対応したインスタンス変数が続いています。「@」で始まるアノテーションの名前から大体の意味は分かるかと思います。中で注意が必要なのは、「private List<Minor> minorList;」変数でしょう。大分類 Major を外部参照している Minor の管理方法が決まります。 Minor は List で管理されます。これはエンティティクラス作成時に、 List を選択したことが影響しています。そのアノテーションは「@OneToMany(cascade = CascadeType.ALL, mappedBy = "major", fetch = FetchType.LAZY)」となっています。「FetchType.LAZY」はフェッチで遅延を選択したためです。
ここで検討が必要なのは、アノテーションを含めて「private List<Minor> minorList;」変数を削除することだと思います。少なくとも変更が望ましいのは「cascade = CascadeType.ALL」の部分でしょう。親のデータに加えた処理がどこまで子供のデータに影響するかに関連します。ここで可能なのは、「ALL, DETACH, MERGE, PERSIST, REFRESH, REMOVE」6種類です。(ちなみにそれぞれ、全機能の場合・管理対象から外れた場合・更新した場合・新規登録した場合・最新に同期した場合・削除した場合 に該当します)ちなみに変更する場合は「PERSIST」がお奨めです。これは親のデータを追加する時にそのデータの minorList に子のデータがあった場合は、Minor テーブルにデータが登録される SQL が自動的に発行されます。標準では ALL です。すると、親のデータを削除すると自動的に子のデータを削除する SQL が発行されることになります。なぜこのような危険な設定が標準となっているのか不思議です。
特にデフォルトのままでエンティティクラスを作成することはやめましょう。「CascadeType.ALL」と「FetchType.DEFAULT」がデフォルトの動作になります。これは危険な組み合わせですよね。親を検索すると、自動的に子・孫・ひ孫とたどれる限り自動検索し、親を削除すると関連するものをすべて削除してしまいます。FetchType はエンティティクラスを作成する時点で指定することができます。しかし CascadeType はクラス生成後に、ソースを直接編集することになります。自動作成されたソースをきちんと確認してください。